弹性能力- HPA & KEDA
弹性能力- HPA & KEDA
K8S原生弹性伸缩-HPA
引入
概念
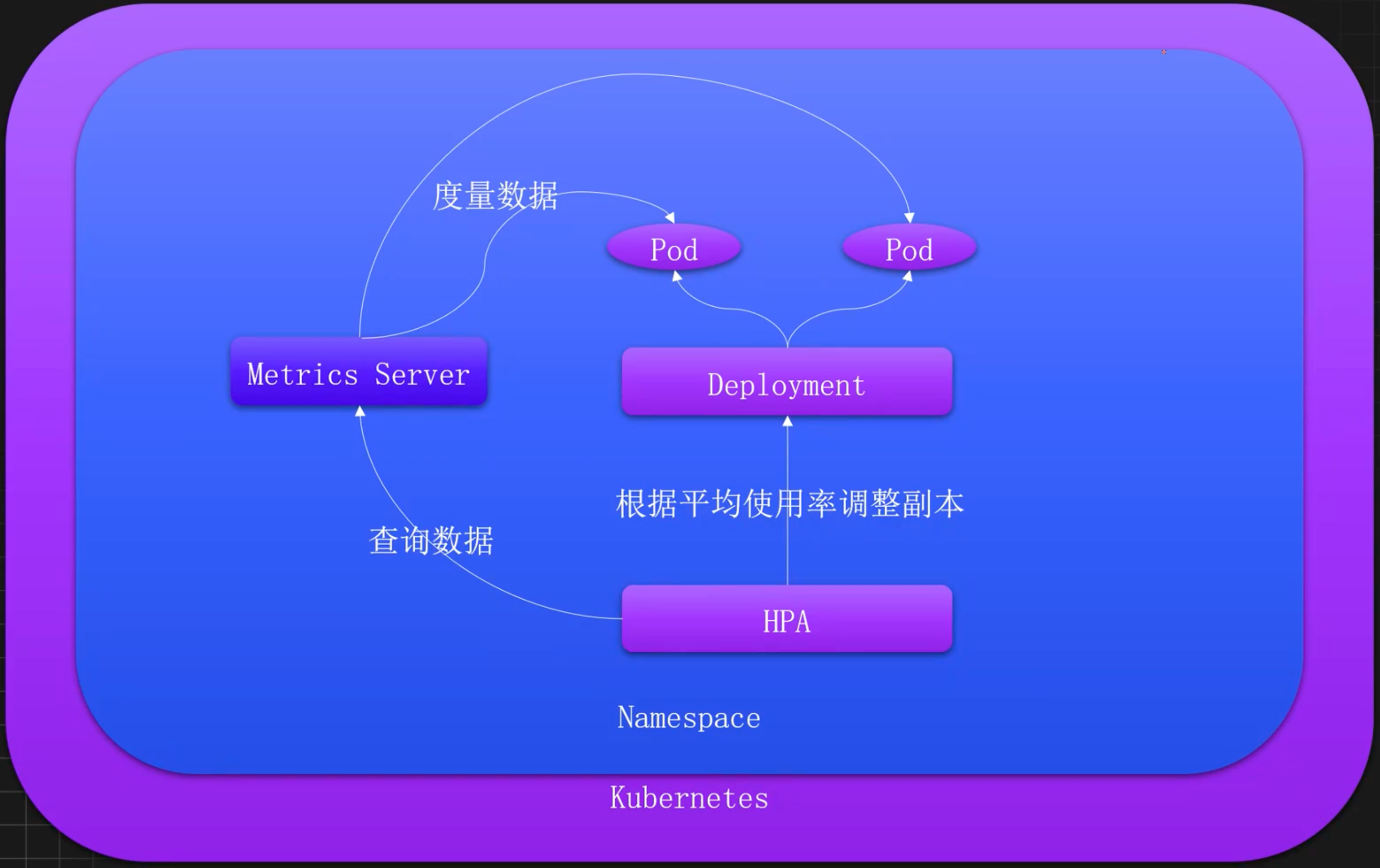
HPA是指Kubernetes水平Pod自动扩缩容(Horizontal Pod Autoscaler)是一个Kubernetes原生的自动化伸缩工具。主要用于根据服务的度量指标(如CPU使用率、内存使用率或其他自定义指标)自动调整服务的副本。
HPA可以通过增加或减少工作负载的副本数来确保应用程序能够处理当前的流量和负载,同时避免资源浪费。
工作流程
资源定义
HPA的资源定义很少通过yaml去创建,一般通过命令或者通过自定义的资源CRD去创建
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50注意事项
针对原生的HPA,与如下注意事项
- 必须安装metrics-server或其他自定义metrics-server
- pod必须配置requests参数
- 不能扩容无法缩放的对象,比如DaemonSet
基于CPU的弹性伸缩
创建测试应用
# vim nginx-server.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-server
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: registry.cn-beijing.aliyuncs.com/dotbalo/nginx:1.15.12
resources:
requests:
memory: "64Mi"
cpu: "10m"
limits:
memory: "128Mi"创建一个Service
kubectl expose deployment nginx-server --port=80创建一个HPA,指定当CPU平均使用率达到10%时触发扩容,且最大副本数为10
kubectl autoscale deployment nginx-server --cpu-percent=10 --min=1 --max=10查看创建的hpa
kubectl get hpa进行压力测试
while true; do wget -q -0- http://10.109.68.255 >/dev/nu1l; done基于内存的弹性伸缩
注意:生产环境中尽量不用基于内存的弹性伸缩
- 内存的不可压缩性问题: 内存资源具有不可压缩性,与CPU不同,当内存压力增大时,添加新的Pod并不能减少原有Pod的内存消耗
- 内存泄漏风险放大:在生产环境中,应用可能存在内存泄漏问题。如果基于内存使用率进行自动伸缩,系统会不断创建新Pod来应对增长的内存需求,而非解决根本的内存泄漏问题
创建测试应用
apiVersion: apps/v1
kind: Deployment
metadta:
name: memory-consumer
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: memory-consumer
template:
metadata:
labels:
app: memory-consumer
spec:
containers:
- name: memory-consumer
image: registry.cn-beijing.aliyuncs.com/dotbalo/stress:latest
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "1024Mi"
cpu: "500m"
args:
- stress
- --vm
- "1"
- --vm-bytes
- "64M"
- --verbose
- --vm-hang
- "3600"查看pod当前内存使用量
kubectl top po创建一个HPA,用于内存到达80%时进行扩容
# vim memory-consumer-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: memory-consumer-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: memory-consumer
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80K8S下一代弹性伸缩-KEDA
引入
什么是KEDA
KEDA(全称:Kubernetes Event-Driven Autoscaler)是一个基于Kubernetes的事件驱动自动伸缩器。使用KEDA,可以根据需要处理的事件数量、消息队列来驱动Kubernetes中任何服务的伸缩。
KEDA的核心思想是:只有有任务需要处理时,才扩展应用程序,并且在没有工作时缩减资源,甚至可以将副本缩容到零。这不仅提高了资源利用率,还降低了成本。
为什么要用KEDA
- 基于事件扩缩容
- 基于消息队列扩缩容
- 基于流量扩缩容
- 基于自定义指标扩缩容
- 基于各种策略扩缩容
KEDA 使用场景
- 基于消息队列的任务处理:KEDA支持从各类消息的数量自动扩缩容相关服务
- 基于HTTP请求的扩缩容:KEDA支持从HTTP请求的数量自动扩缩容相关服务
- 定时任务和批处理:KEDA支持时间的触发器,定时进行扩缩容
- 无服务架构:KEDA支持ScaletoZero,功能和Serverless类似
KEDA架构
ScaledObject:KEDA核心资源,用于定义扩缩容规则Controller: KEDA控制器, 监听APIServer的KEDA对象,并根据规则通知Scaler调整副本数量Scaler:Scaler与HPA协同工作,以实现自动扩展ExternalTrigger Source:外部事件或数据源,可以触发KEDA的扩展操作MetricsAdapter:用于定义自定义指标
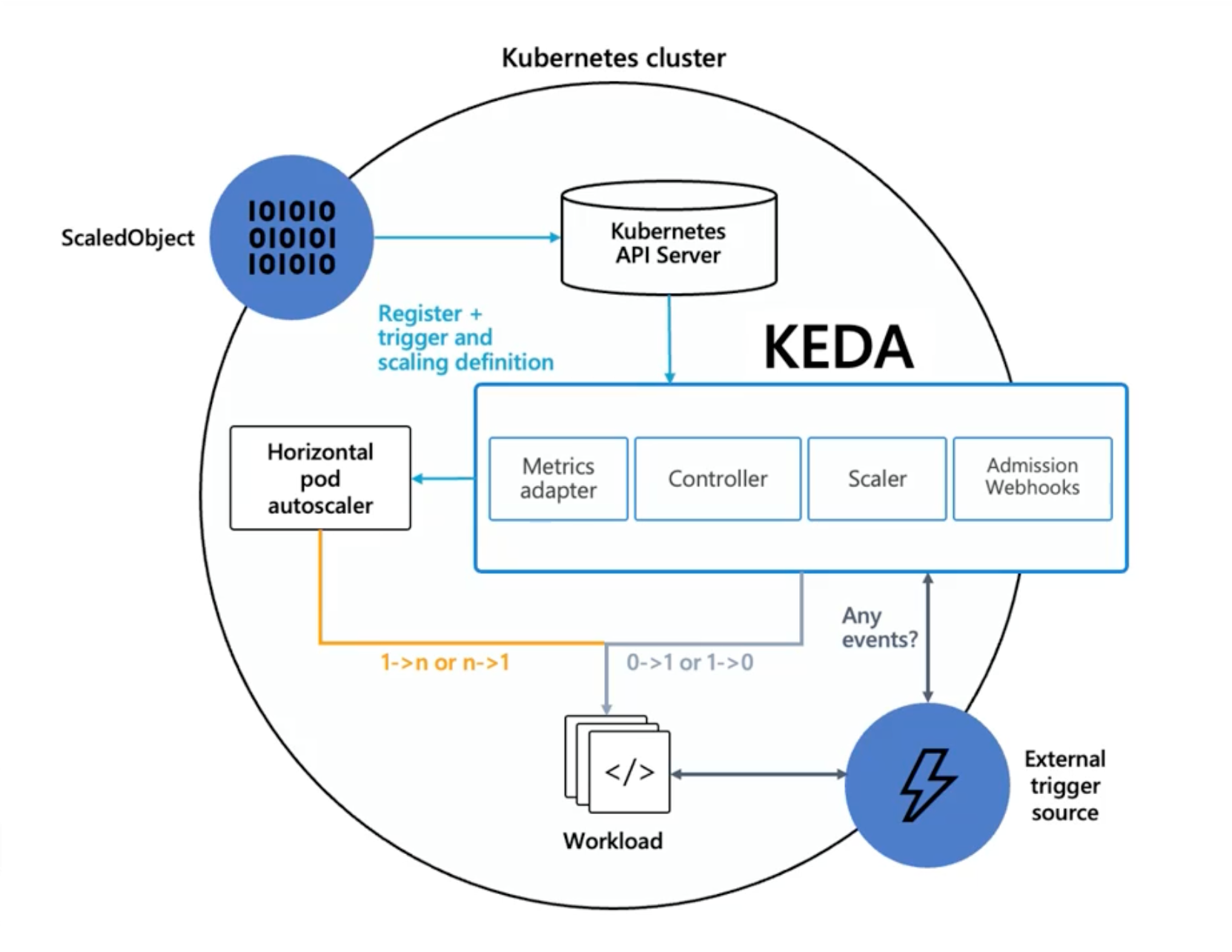
核心资源
ScaledObject:用于控制Deployment等资源的副本数,可以指定多种事件和消息来源控制资源的副本数,同时支持ScaletoZero(用于扩缩容Deployment、StatefulSet)ScaledJob:用于触发一次性Job任务,可以根据多种外部事件源触发创建一次性任务,主要用于处理批处理任务或临时任务,类似Serverless(用于创建Job)TriggerAuthentication:用于管理KEDA Scaler与外部事件源(如RabbitMQ、AWS SQS、AzureQueue等)之间的身份验证和授权,支持环境变量、ConfigMap、Secret等(用于外部事件源身份认证)
资源定义
ScaledObject资源定义
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: video-processing-scaledobject
namespace: default
spec:
scaleTarget = Ref:
name: order-processor # 目标 Deployment 名称
pollingInterval: 30 # 每 30 秒检查一次队列
cooldownPeriod: 300 # 扩缩容后等待 5 分钟
minReplicaCount: 1 # 最少保持 1 个副本
maxReplicaCount: 10 # 最多扩展到 10 个副本
triggers:
- type: rabbitmq
metadata:
queueName: "video-processing-queue" # RabbitMQ 队列名称
mode: QueueLength # 监听类型
value: "50" # 当队列中每个实例平均消息 50 条及以上消息时触发扩容
authenticationRef: # 认证
name: keda-trigger-auth-rabbitmq-conn # TriggerAuthentication 名称ScaledJob资源定义
apiVersion: keda. sh/vlalpha
kind: ScaledJob
metadata:
name: video-processing-scaledjob
namespace: default
spec:
jobTargetRef:
parallelism: 1 # 每次只创建一个 Job 实例
completions: 1 # 每个 Job 只运行一次
template:
spec:
containers:
- name: video-processor
image: xxx:test # 你的镜像
pollingInterval: 30 # 每 30 秒检查一次队列
maxReplicaCount: 10 # 最多同时运行 10 个 Job
successfulJobsHistoryLimit: 3 # 保留 3 个成功的 Job 历史
failedJobsHistoryLimit: 1 # 保留 1 个失败的 Job 历史
triggers:
- type: rabbitmqTriggerAuthentication 资源定义
[更多类型](https: //keda. sh/docs/2. 16/authentication-providers/)
---
apiVersion: v1
kind: Secret
metadata:
name: mysql-secrets
namespace: my-project
type: Opaque
dataString:
mysql_conn_str: user:password@tcp(mysql:3306)/stats_db
---
apiVersion: keda. sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-mysql-secret
namespace: my-project
spec:
# 基于secret
secretTargetRef:
- parameter: connectionString # Scaler 参数名字(可以在官网查询可以填哪些值)
name: mysql-secrets # secret名称
key: mysql_conn_str # key名称
# 基于configMap
# configMapTargetRef:
# - parameter: connectionString
# name: my-keda-configmap-resource-name
# key: azure-storage-connectionstring
# 基于env环境变量
# env:
# - parameter: region
# name: my-env-var
# containerName: my-container
---
apiVersion: keda. sh/v1alpha
kind: ScaledObject
metadata:
name: mysql-scaledobject
namespace: my-project
spec:
scaleTargetRef:
name: worker
triggers:
- type: mysql
authenticationRef:
name: keda-trigger-auth-mysql-secret部署KEDA
# 添加 KEDA 的 Helm 源
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
# 安装KEDA
helm install keda kedacore/keda --namespace keda --create-namespace
# 查看服务状态
kubectl get po -n keda
# 查看自定义资源
kubectl api-resources | grep keda案例
周期性扩缩容
KEDA 支持周期性弹性收缩服务,且支持缩容至 0。假设有个服务只有每天早上 7-9 点属于业务峰,就可以利用 KEDA 实现在 7-9 点扩展服务,除此之外的时间在缩减副本,以节省资源。
创建 Cron 类型的 ScaledObject
# vim cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
scaleTargetRef:
name: nginx-server
minReplicaCount: 1 # 最低副本
cooldownPeriod: 300 # 冷却期,到 end 时间后,多久缩容
triggers:
- type: cron
metadata:
timezone: Asia/Shanghai
start: "00 07 * * *"
end: "00 09 * * *"
desiredReplicas: "3" # 扩容后的副本数查看状态
# 查看 ScaledObject 状态
kubectl get so
# 查看创建的 HPA
kubectl get hpa
# 查看扩容后的状态
kubectl get po基于RabbitMQ消息队列扩缩容
KEDA 支持基于消息队列的弹性伸缩,比如基于 RabbitMQ、Kafka、Redis 队列进行扩缩容, 以便更快的处理处理。
首先创建一个 RabbitMQ
# vim rabbitmq.yaml
apiVersion: v1
kind: Service
metadata:
name: rabbitmq
spec:
ports:
- name: web
port: 5672
protocol: TCP
targetPort: 5672
- name: http
port: 15672
protocol: TCP
targetPort: 15672
selector:
app: rabbitmq
sessionAffinity: None
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
annotations: {}
labels:
app: rabbitmq
name: rabbitmq
spec:
replicas: 1
selector:
matchLabels:
app: rabbitmq
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: rabbitmq
spec:
affinity: {}
containers:
- env:
- name: TZ
value: Asia/Shanghai
- name: LANG
value: C.UTF-8
- name: RABBITMQ_DEFAULT_USER
value: user
- name: RABBITMQ_DEFAULT_PASS
value: password
image: registry.cn-beijing.aliyuncs.com/dotbalo/rabbitmq:4.0.5-management-alpine
imagePullPolicy: IfNotPresent
lifecycle: {}
livenessProbe:
failureThreshold: 2
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 5672
timeoutSeconds: 2
name: rabbitmq
ports:
- containerPort: 5672
name: web
protocol: TCP
readinessProbe:
failureThreshold: 2
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 5672
timeoutSeconds: 2查看状态
# 查看 Pod 和 Service
kubectl get po
kubectl get svc
# 访问测试使用一个 Job 模拟写入消息
# vim rabbitmq-publish-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: rabbitmq-publish
spec:
template:
spec:
containers:
- name: rabbitmq-client
image: registry.cn-beijing.aliyuncs.com/dotbalo/rabbitmqpublish:v1.0
imagePullPolicy: IfNotPresent
command:
- "send"
- "amqp://user:password@rabbitmq.default.svc.cluster.local:5672"
- "10"
restartPolicy: Never
backoffLimit: 4查看消息队列
创建一个模拟消费消息的程序
# vim rabbitmq-consumer.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: rabbitmq-consumer
namespace: default
labels:
app: rabbitmq-consumer
spec:
selector:
matchLabels:
app: rabbitmq-consumer
template:
metadata:
labels:
app: rabbitmq-consumer
spec:
containers:
- name: rabbitmq-consumer
image: registry.cn-beijing.aliyuncs.com/dotbalo/rabbitmqconsumer:v1.0
imagePullPolicy: Always
command:
- receive
args:
- "amqp://user:password@rabbitmq.default.svc.cluster.local:5672"创建 TriggerAuthentication
# vim rabbitTriggerAuth.yaml
apiVersion: v1
kind: Secret
metadata:
name: keda-rabbitmq-secret
stringData:
host: amqp://user:password@rabbitmq:5672 # amqp 地址
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-rabbitmq-conn
spec:
secretTargetRef:
- parameter: host
name: keda-rabbitmq-secret
key: host创建 ScaledObject
# rabbitmq-so.yaml
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-scaledobject
spec:
scaleTargetRef:
name: rabbitmq-consumer
pollingInterval: 5 # 检查周期,默认 5 秒
cooldownPeriod: 30 # 冷却时间,默认 300 秒
minReplicaCount: 1
maxReplicaCount: 30 # 最大副本数
triggers:
- type: rabbitmq
metadata:
protocol: amqp
queueName: hello
mode: QueueLength # 监听模式,队列长度(QueueLength)或消息速率(MessageRate)
value: "50" # 消息数或每秒速率
authenticationRef:
name: keda-trigger-auth-rabbitmq-conn写入消息
kubectl delete -f rabbitmq-publish-job.yaml
kubectl create -f rabbitmq-publish-job.yaml查看消息
查看扩容情况
kubectl get hpa
kubectl get po当消息处理完以后,副本会被缩减
kubectl get hpa
kubectl get po卸载服务
kubectl delete -f rabbitmq-consumer.yaml -f rabbitmq-so.yaml -f rabbitTriggerAuth.yaml -f rabbitmq-publish-job.yaml